Natural Language Processing (NLP) • Large Language Models (LLM) • Trustworthy AI (TrustAI) • Machine Learning for Healthcare (ML for Health) • Evaluation and Metrics (Eval) • Conversational AI (ConvAI) • Human-Robot Interaction (HRI)
I am a Principal AI Scientist at Vanguard, specializing in artificial intelligence research with a focus on computational models of natural language processing. My work includes AI-powered natural language generation, machine learning applications for detecting cognitive impairment and mental health issues, and advancing human-robot interaction through AI systems.
With a PhD in Computer Science from the University of Bath, UK, I bring over a decade of experience in artificial intelligence research across industry, academia, and non-profit organizations. My machine learning solutions have created practical impact, from developing healthcare tools for clinical trials and senior care applications to programming a humanoid robot that engages customers in shopping environments using advanced natural language processing techniques.
As an advocate for open-source artificial intelligence, I have contributed to major AI projects including BLOOM LLM and BIG-Bench, working toward more reliable and accessible AI technologies. My work in machine learning research focuses on ensuring ethical AI development and has established me as a respected voice in the field.
I was fortunate to work with brilliant researchers in the field. I have worked, among many others, with Joana Bryson (now at Hertie School in Berlin, Germany), with Verena Rieser (now at Google DeepMind), with Oliver Lemon at the Heriot-Watt University in Edinburgh, UK, and with Frank Rudzicz (now at Dalhousie University in Halifax, Canada).
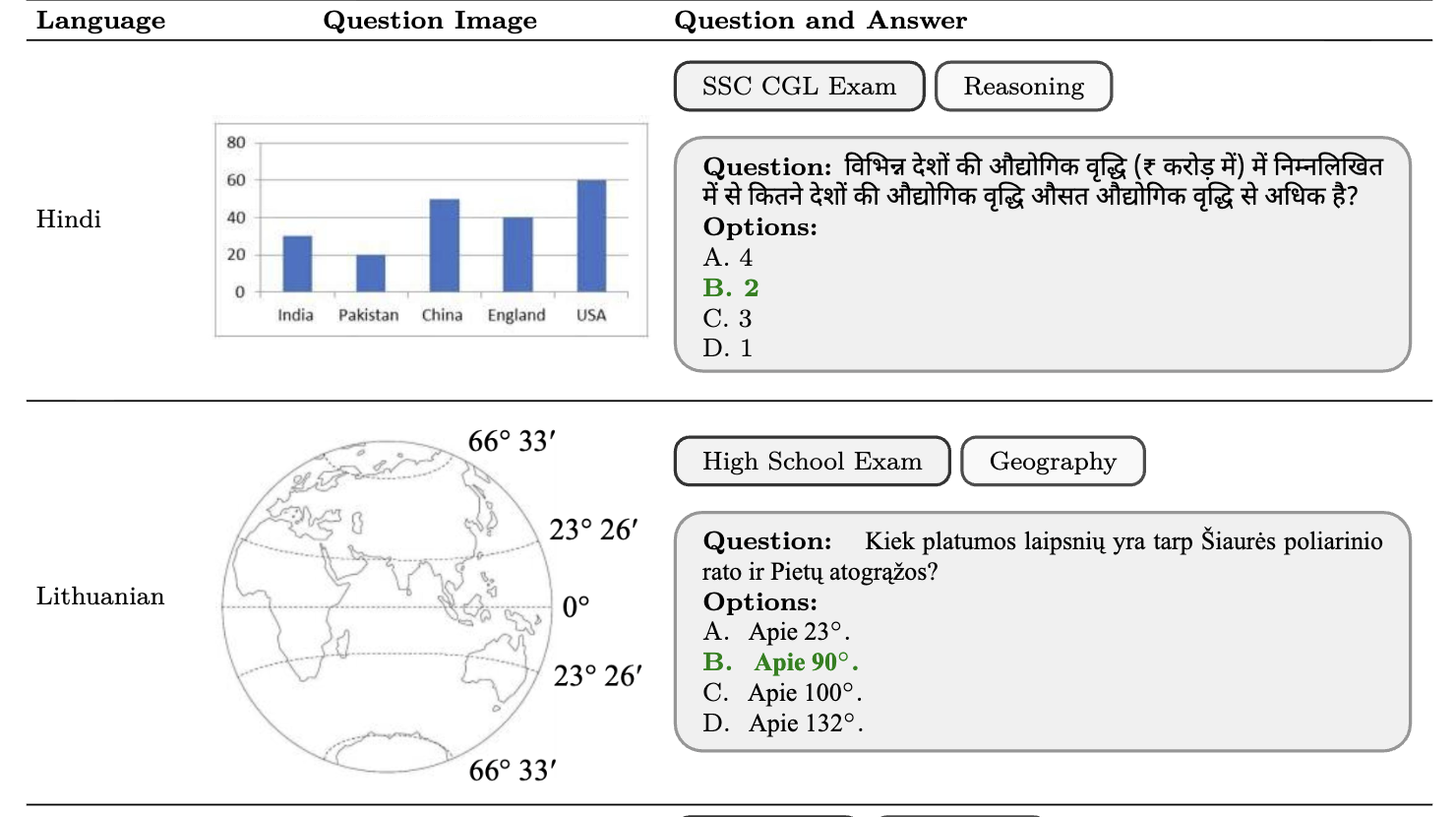
The performance differential of large language models (LLM) between languages hinders their effective deployment in many regions, inhibiting the potential economic and societal value of generative AI tools in many communities. However, the development of functional LLMs in many languages (\ie, multilingual LLMs) is bottlenecked by the lack of high-quality evaluation resources in languages other than English. Moreover, current practices in multilingual benchmark construction often translate English resources, ignoring the regional and cultural knowledge of the environments in which multilingual systems would be used. In this work, we construct an evaluation suite of 197,243 QA pairs from local exam sources to measure the capabilities of multilingual LLMs in a variety of regional contexts. Our novel resource, INCLUDE, is a comprehensive knowledge- and reasoning-centric benchmark across 44 written languages that evaluates multilingual LLMs for performance in the actual language environments where they would be deployed.
@inproceedings{romanou2025include,title={{INCLUDE}: Evaluating Multilingual Language Understanding with Regional Knowledge},author={Romanou, Angelika and Foroutan, Negar and Sotnikova, Anna and Nelaturu, Sree Harsha and Singh, Shivalika and Maheshwary, Rishabh and Altomare, Micol and Chen, Zeming and Haggag, Mohamed A. and A, Snegha and Amayuelas, Alfonso and Amirudin, Azril Hafizi and Boiko, Danylo and Chang, Michael and Chim, Jenny and Cohen, Gal and Dalmia, Aditya Kumar and Diress, Abraham and Duwal, Sharad and Dzenhaliou, Daniil and Florez, Daniel Fernando Erazo and Farestam, Fabian and Imperial, Joseph Marvin and Islam, Shayekh Bin and Isotalo, Perttu and Jabbarishiviari, Maral and Karlsson, B{\"o}rje F. and Khalilov, Eldar and Klamm, Christopher and Koto, Fajri and Krzemi{\'n}ski, Dominik and de Melo, Gabriel Adriano and Montariol, Syrielle and Nan, Yiyang and Niklaus, Joel and Novikova, Jekaterina and Ceron, Johan Samir Obando and Paul, Debjit and Ploeger, Esther and Purbey, Jebish and Rajwal, Swati and Ravi, Selvan Sunitha and Rydell, Sara and Santhosh, Roshan and Sharma, Drishti and Skenduli, Marjana Prifti and Moakhar, Arshia Soltani and soltani moakhar, Bardia and Tarun, Ayush Kumar and Wasi, Azmine Toushik and Weerasinghe, Thenuka Ovin and Yilmaz, Serhan and Zhang, Mike and Schlag, Imanol and Fadaee, Marzieh and Hooker, Sara and Bosselut, Antoine},booktitle={The Thirteenth International Conference on Learning Representations},year={2024},url={https://openreview.net/forum?id=k3gCieTXeY},}
LLM
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
BigScience Workshop, :, Teven Le Scao, and 391 more authors
Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
@misc{workshop2023bloom176bparameteropenaccessmultilingual,title={BLOOM: A 176B-Parameter Open-Access Multilingual Language Model},author={Workshop, BigScience and : and Scao, Teven Le and Fan, Angela and Akiki, Christopher and Pavlick, Ellie and Ilić, Suzana and Hesslow, Daniel and Castagné, Roman and Luccioni, Alexandra Sasha and Yvon, François and Gallé, Matthias and Tow, Jonathan and Rush, Alexander M. and Biderman, Stella and Webson, Albert and Ammanamanchi, Pawan Sasanka and Wang, Thomas and Sagot, Benoît and Muennighoff, Niklas and del Moral, Albert Villanova and Ruwase, Olatunji and Bawden, Rachel and Bekman, Stas and McMillan-Major, Angelina and Beltagy, Iz and Nguyen, Huu and Saulnier, Lucile and Tan, Samson and Suarez, Pedro Ortiz and Sanh, Victor and Laurençon, Hugo and Jernite, Yacine and Launay, Julien and Mitchell, Margaret and Raffel, Colin and Gokaslan, Aaron and Simhi, Adi and Soroa, Aitor and Aji, Alham Fikri and Alfassy, Amit and Rogers, Anna and Nitzav, Ariel Kreisberg and Xu, Canwen and Mou, Chenghao and Emezue, Chris and Klamm, Christopher and Leong, Colin and van Strien, Daniel and Adelani, David Ifeoluwa and Radev, Dragomir and Ponferrada, Eduardo González and Levkovizh, Efrat and Kim, Ethan and Natan, Eyal Bar and Toni, Francesco De and Dupont, Gérard and Kruszewski, Germán and Pistilli, Giada and Elsahar, Hady and Benyamina, Hamza and Tran, Hieu and Yu, Ian and Abdulmumin, Idris and Johnson, Isaac and Gonzalez-Dios, Itziar and de la Rosa, Javier and Chim, Jenny and Dodge, Jesse and Zhu, Jian and Chang, Jonathan and Frohberg, Jörg and Tobing, Joseph and Bhattacharjee, Joydeep and Almubarak, Khalid and Chen, Kimbo and Lo, Kyle and Werra, Leandro Von and Weber, Leon and Phan, Long and allal, Loubna Ben and Tanguy, Ludovic and Dey, Manan and Muñoz, Manuel Romero and Masoud, Maraim and Grandury, María and Šaško, Mario and Huang, Max and Coavoux, Maximin and Singh, Mayank and Jiang, Mike Tian-Jian and Vu, Minh Chien and Jauhar, Mohammad A. and Ghaleb, Mustafa and Subramani, Nishant and Kassner, Nora and Khamis, Nurulaqilla and Nguyen, Olivier and Espejel, Omar and de Gibert, Ona and Villegas, Paulo and Henderson, Peter and Colombo, Pierre and Amuok, Priscilla and Lhoest, Quentin and Harliman, Rheza and Bommasani, Rishi and López, Roberto Luis and Ribeiro, Rui and Osei, Salomey and Pyysalo, Sampo and Nagel, Sebastian and Bose, Shamik and Muhammad, Shamsuddeen Hassan and Sharma, Shanya and Longpre, Shayne and Nikpoor, Somaieh and Silberberg, Stanislav and Pai, Suhas and Zink, Sydney and Torrent, Tiago Timponi and Schick, Timo and Thrush, Tristan and Danchev, Valentin and Nikoulina, Vassilina and Laippala, Veronika and Lepercq, Violette and Prabhu, Vrinda and Alyafeai, Zaid and Talat, Zeerak and Raja, Arun and Heinzerling, Benjamin and Si, Chenglei and Taşar, Davut Emre and Salesky, Elizabeth and Mielke, Sabrina J. and Lee, Wilson Y. and Sharma, Abheesht and Santilli, Andrea and Chaffin, Antoine and Stiegler, Arnaud and Datta, Debajyoti and Szczechla, Eliza and Chhablani, Gunjan and Wang, Han and Pandey, Harshit and Strobelt, Hendrik and Fries, Jason Alan and Rozen, Jos and Gao, Leo and Sutawika, Lintang and Bari, M Saiful and Al-shaibani, Maged S. and Manica, Matteo and Nayak, Nihal and Teehan, Ryan and Albanie, Samuel and Shen, Sheng and Ben-David, Srulik and Bach, Stephen H. and Kim, Taewoon and Bers, Tali and Fevry, Thibault and Neeraj, Trishala and Thakker, Urmish and Raunak, Vikas and Tang, Xiangru and Yong, Zheng-Xin and Sun, Zhiqing and Brody, Shaked and Uri, Yallow and Tojarieh, Hadar and Roberts, Adam and Chung, Hyung Won and Tae, Jaesung and Phang, Jason and Press, Ofir and Li, Conglong and Narayanan, Deepak and Bourfoune, Hatim and Casper, Jared and Rasley, Jeff and Ryabinin, Max and Mishra, Mayank and Zhang, Minjia and Shoeybi, Mohammad and Peyrounette, Myriam and Patry, Nicolas and Tazi, Nouamane and Sanseviero, Omar and von Platen, Patrick and Cornette, Pierre and Lavallée, Pierre François and Lacroix, Rémi and Rajbhandari, Samyam and Gandhi, Sanchit and Smith, Shaden and Requena, Stéphane and Patil, Suraj and Dettmers, Tim and Baruwa, Ahmed and Singh, Amanpreet and Cheveleva, Anastasia and Ligozat, Anne-Laure and Subramonian, Arjun and Névéol, Aurélie and Lovering, Charles and Garrette, Dan and Tunuguntla, Deepak and Reiter, Ehud and Taktasheva, Ekaterina and Voloshina, Ekaterina and Bogdanov, Eli and Winata, Genta Indra and Schoelkopf, Hailey and Kalo, Jan-Christoph and Novikova, Jekaterina and Forde, Jessica Zosa and Clive, Jordan and Kasai, Jungo and Kawamura, Ken and Hazan, Liam and Carpuat, Marine and Clinciu, Miruna and Kim, Najoung and Cheng, Newton and Serikov, Oleg and Antverg, Omer and van der Wal, Oskar and Zhang, Rui and Zhang, Ruochen and Gehrmann, Sebastian and Mirkin, Shachar and Pais, Shani and Shavrina, Tatiana and Scialom, Thomas and Yun, Tian and Limisiewicz, Tomasz and Rieser, Verena and Protasov, Vitaly and Mikhailov, Vladislav and Pruksachatkun, Yada and Belinkov, Yonatan and Bamberger, Zachary and Kasner, Zdeněk and Rueda, Alice and Pestana, Amanda and Feizpour, Amir and Khan, Ammar and Faranak, Amy and Santos, Ana and Hevia, Anthony and Unldreaj, Antigona and Aghagol, Arash and Abdollahi, Arezoo and Tammour, Aycha and HajiHosseini, Azadeh and Behroozi, Bahareh and Ajibade, Benjamin and Saxena, Bharat and Ferrandis, Carlos Muñoz and McDuff, Daniel and Contractor, Danish and Lansky, David and David, Davis and Kiela, Douwe and Nguyen, Duong A. and Tan, Edward and Baylor, Emi and Ozoani, Ezinwanne and Mirza, Fatima and Ononiwu, Frankline and Rezanejad, Habib and Jones, Hessie and Bhattacharya, Indrani and Solaiman, Irene and Sedenko, Irina and Nejadgholi, Isar and Passmore, Jesse and Seltzer, Josh and Sanz, Julio Bonis and Dutra, Livia and Samagaio, Mairon and Elbadri, Maraim and Mieskes, Margot and Gerchick, Marissa and Akinlolu, Martha and McKenna, Michael and Qiu, Mike and Ghauri, Muhammed and Burynok, Mykola and Abrar, Nafis and Rajani, Nazneen and Elkott, Nour and Fahmy, Nour and Samuel, Olanrewaju and An, Ran and Kromann, Rasmus and Hao, Ryan and Alizadeh, Samira and Shubber, Sarmad and Wang, Silas and Roy, Sourav and Viguier, Sylvain and Le, Thanh and Oyebade, Tobi and Le, Trieu and Yang, Yoyo and Nguyen, Zach and Kashyap, Abhinav Ramesh and Palasciano, Alfredo and Callahan, Alison and Shukla, Anima and Miranda-Escalada, Antonio and Singh, Ayush and Beilharz, Benjamin and Wang, Bo and Brito, Caio and Zhou, Chenxi and Jain, Chirag and Xu, Chuxin and Fourrier, Clémentine and Periñán, Daniel León and Molano, Daniel and Yu, Dian and Manjavacas, Enrique and Barth, Fabio and Fuhrimann, Florian and Altay, Gabriel and Bayrak, Giyaseddin and Burns, Gully and Vrabec, Helena U. and Bello, Imane and Dash, Ishani and Kang, Jihyun and Giorgi, John and Golde, Jonas and Posada, Jose David and Sivaraman, Karthik Rangasai and Bulchandani, Lokesh and Liu, Lu and Shinzato, Luisa and de Bykhovetz, Madeleine Hahn and Takeuchi, Maiko and Pàmies, Marc and Castillo, Maria A and Nezhurina, Marianna and Sänger, Mario and Samwald, Matthias and Cullan, Michael and Weinberg, Michael and Wolf, Michiel De and Mihaljcic, Mina and Liu, Minna and Freidank, Moritz and Kang, Myungsun and Seelam, Natasha and Dahlberg, Nathan and Broad, Nicholas Michio and Muellner, Nikolaus and Fung, Pascale and Haller, Patrick and Chandrasekhar, Ramya and Eisenberg, Renata and Martin, Robert and Canalli, Rodrigo and Su, Rosaline and Su, Ruisi and Cahyawijaya, Samuel and Garda, Samuele and Deshmukh, Shlok S and Mishra, Shubhanshu and Kiblawi, Sid and Ott, Simon and Sang-aroonsiri, Sinee and Kumar, Srishti and Schweter, Stefan and Bharati, Sushil and Laud, Tanmay and Gigant, Théo and Kainuma, Tomoya and Kusa, Wojciech and Labrak, Yanis and Bajaj, Yash Shailesh and Venkatraman, Yash and Xu, Yifan and Xu, Yingxin and Xu, Yu and Tan, Zhe and Xie, Zhongli and Ye, Zifan and Bras, Mathilde and Belkada, Younes and Wolf, Thomas},year={2023},eprint={2211.05100},archiveprefix={arXiv},primaryclass={cs.CL},url={https://arxiv.org/abs/2211.05100},}
Eval
Why We Need New Evaluation Metrics for NLG
Jekaterina Novikova, Ondřej Dušek, Amanda Cercas Curry, and 1 more author
In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Sep 2017
The majority of NLG evaluation relies on automatic metrics, such as BLEU . In this paper, we motivate the need for novel, system- and data-independent automatic evaluation methods: We investigate a wide range of metrics, including state-of-the-art word-based and novel grammar-based ones, and demonstrate that they only weakly reflect human judgements of system outputs as generated by data-driven, end-to-end NLG. We also show that metric performance is data- and system-specific. Nevertheless, our results also suggest that automatic metrics perform reliably at system-level and can support system development by finding cases where a system performs poorly.
@inproceedings{novikova-etal-2017-need,title={Why We Need New Evaluation Metrics for {NLG}},author={Novikova, Jekaterina and Du{\v{s}}ek, Ond{\v{r}}ej and Cercas Curry, Amanda and Rieser, Verena},editor={Palmer, Martha and Hwa, Rebecca and Riedel, Sebastian},booktitle={Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing},month=sep,year={2017},address={Copenhagen, Denmark},publisher={Association for Computational Linguistics},url={https://aclanthology.org/D17-1238/},doi={10.18653/v1/D17-1238},pages={2241--2252},dimensions={true},}