Publications
Select publications only. See my Google Scholar profile for a full list of publications.
2026
- Reliability
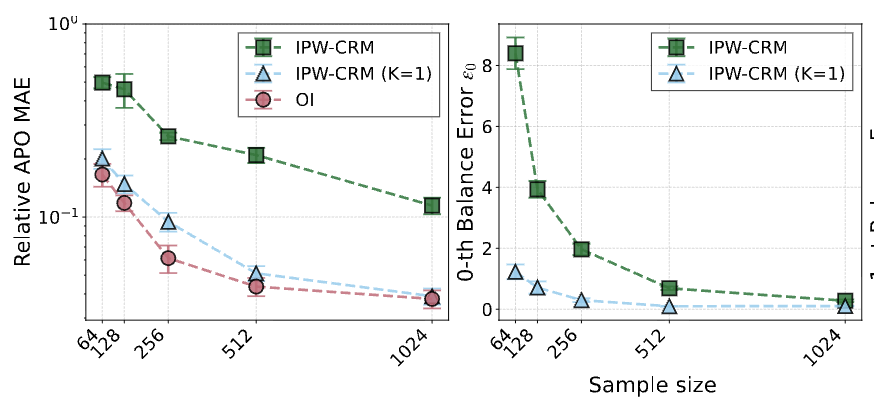 Causal Risk Minimization for High-Dimensional TreatmentsNikita Dhawan, Arnav Paruthi, Andrew Kim, and 3 more authorsIn The ICML 2026 Workshop on Hypothesis Testing, 2026
Causal Risk Minimization for High-Dimensional TreatmentsNikita Dhawan, Arnav Paruthi, Andrew Kim, and 3 more authorsIn The ICML 2026 Workshop on Hypothesis Testing, 2026Predicting the effect of interventions with many possible variations, e.g., therapeutic content that affects mental health outcomes or an earnings call transcript that drives movement in share price, is useful across several domains. However, classical causal estimators tend to assume that all possible interventions are observed, which is infeasible when interventions vary widely, for instance, in the space of all text strings. We adapt a well-known approach of recasting causal inference as a learning problem, to address high-dimensional treatment spaces. Specifically, under standard assumptions like no unobserved confounding, we show that causal error decomposes into a series of moment-balancing errors of increasing order, and design objectives that directly improve causal estimation. We also show how to project the effect of a high-dimensional treatment onto lower-dimensional treatment attributes, which allows a single model to answer several causal questions without additional attribute-specific training. We empirically evaluate our estimators in settings with high-dimensional continuous, discrete, and text treatments, the last of which used a semi-synthetic dataset of Amazon Reviews. Our experiments demonstrate the benefit of higher-order balance error optimization and competitive performance of projected causal estimates with attribute-specific estimators.
@inproceedings{dhawan2026causal, title = {Causal Risk Minimization for High-Dimensional Treatments}, author = {Dhawan, Nikita and Paruthi, Arnav and Kim, Andrew and Gondara, Lovedeep and Novikova, Jekaterina and Maddison, Chris J.}, booktitle = {The ICML 2026 Workshop on Hypothesis Testing}, year = {2026}, url = {https://openreview.net/forum?id=WR3XMPiVjj}, } - Eval
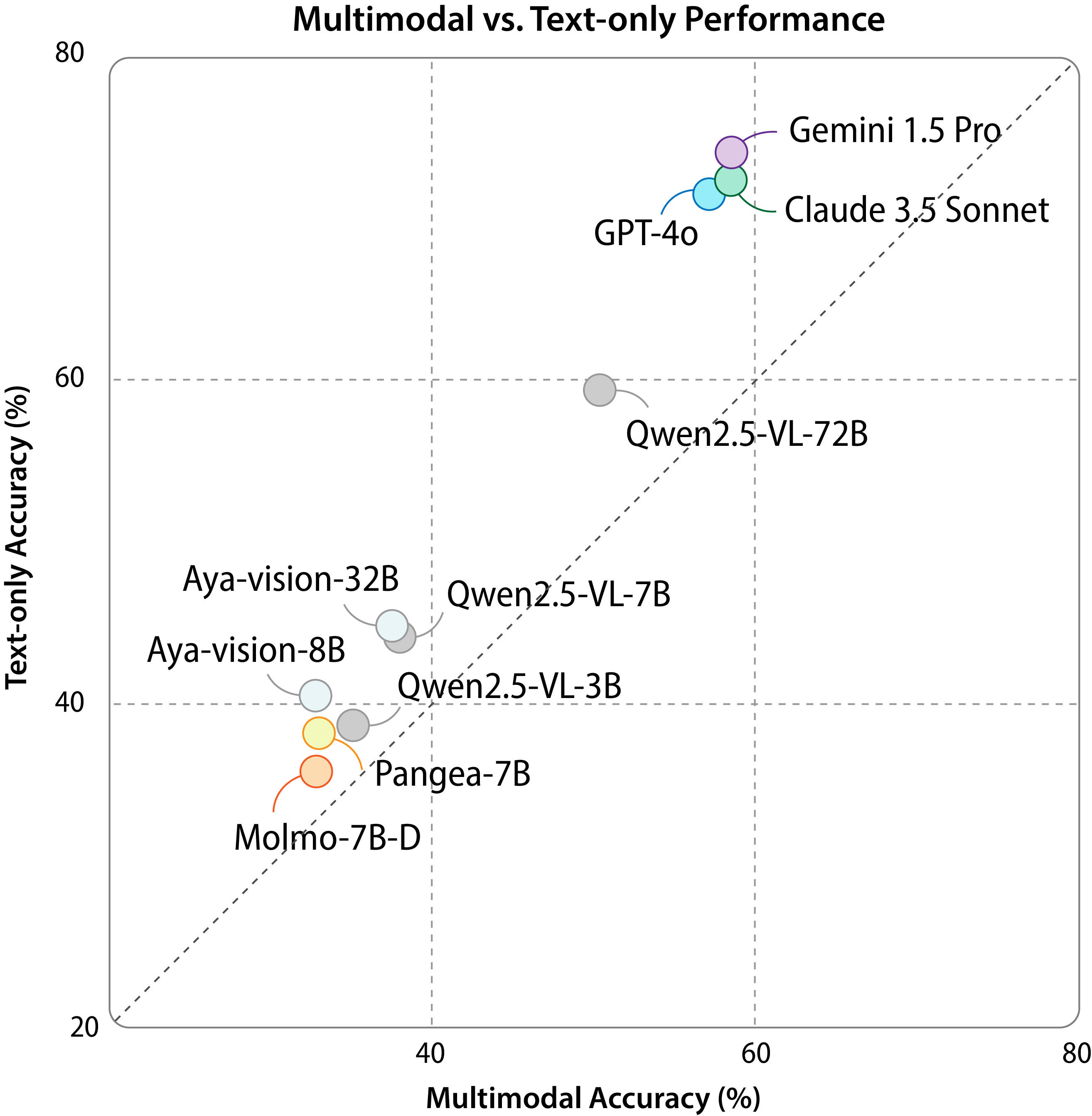 Kaleidoscope: In-language Exams for Massively Multilingual Vision EvaluationIsrafel Salazar, Manuel Fernández Burda, Shayekh Bin Islam, and 42 more authorsIn The Fourteenth International Conference on Learning Representations, 2026
Kaleidoscope: In-language Exams for Massively Multilingual Vision EvaluationIsrafel Salazar, Manuel Fernández Burda, Shayekh Bin Islam, and 42 more authorsIn The Fourteenth International Conference on Learning Representations, 2026The evaluation of vision-language models (VLMs) has mainly relied on English-language benchmarks, leaving significant gaps in both multilingual and multicultural coverage. While multilingual benchmarks have expanded, both in size and languages, many rely on translations of English datasets, failing to capture cultural nuances. In this work, we propose Kaleidoscope, as the most comprehensive exam benchmark to date for the multilingual evaluation of vision-language models. Kaleidoscope is a large-scale, in-language multimodal benchmark designed to evaluate VLMs across diverse languages and visual inputs. Kaleidoscope covers 18 languages and 14 different subjects, amounting to a total of 20,911 multiple-choice questions. Built through an open science collaboration with a diverse group of researchers worldwide, Kaleidoscope ensures linguistic and cultural authenticity. We evaluate top-performing multilingual vision-language models and find that they perform poorly on low-resource languages and in complex multimodal scenarios. Our results highlight the need for progress on culturally inclusive multimodal evaluation frameworks.
@inproceedings{salazar2025kaleidoscopeinlanguageexamsmassively, title = {Kaleidoscope: In-language Exams for Massively Multilingual Vision Evaluation}, author = {Salazar, Israfel and Burda, Manuel Fernández and Islam, Shayekh Bin and Moakhar, Arshia Soltani and Singh, Shivalika and Farestam, Fabian and Romanou, Angelika and Boiko, Danylo and Khullar, Dipika and Zhang, Mike and Krzemiński, Dominik and Novikova, Jekaterina and Shimabucoro, Luísa and Imperial, Joseph Marvin and Maheshwary, Rishabh and Duwal, Sharad and Amayuelas, Alfonso and Rajwal, Swati and Purbey, Jebish and Ruby, Ahmed and Popovič, Nicholas and Suppa, Marek and Wasi, Azmine Toushik and Kadiyala, Ram Mohan Rao and Tsymboi, Olga and Kostritsya, Maksim and Moakhar, Bardia Soltani and da Costa Merlin, Gabriel and Coletti, Otávio Ferracioli and Shiviari, Maral Jabbari and farahani fard, MohammadAmin and Fernandez, Silvia and Grandury, María and Abulkhanov, Dmitry and Sharma, Drishti and Mitri, Andre Guarnier De and Marchezi, Leticia Bossatto and Heydari, Setayesh and Obando-Ceron, Johan and Kohut, Nazar and Ermis, Beyza and Elliott, Desmond and Ferrante, Enzo and Hooker, Sara and Fadaee, Marzieh}, booktitle = {The Fourteenth International Conference on Learning Representations}, year = {2026}, url = {https://openreview.net/forum?id=zCYXhSy9UH}, }
2025
- Reliability
 Consistency in Language Models: Current Landscape, Challenges, and Future DirectionsJekaterina Novikova, Carol Myrick Anderson, Borhane Blili-Hamelin, and 1 more authorIn ICML 2025 Workshop on Reliable and Responsible Foundation Models, 2025
Consistency in Language Models: Current Landscape, Challenges, and Future DirectionsJekaterina Novikova, Carol Myrick Anderson, Borhane Blili-Hamelin, and 1 more authorIn ICML 2025 Workshop on Reliable and Responsible Foundation Models, 2025The hallmark of effective language use lies in consistency: expressing similar meanings in similar contexts and avoiding contradictions. While human communication naturally demonstrates this principle, state-of-the-art language models (LMs) struggle to maintain reliable consistency across task- and domain-specific applications. Here we examine the landscape of consistency research in LMs, analyze current approaches to measure aspects of consistency, and identify critical research gaps. Our findings point to an urgent need for quality benchmarks to measure and interdisciplinary approaches to ensure consistency while preserving utility.
@inproceedings{novikova2025consistency, title = {Consistency in Language Models: Current Landscape, Challenges, and Future Directions}, author = {Novikova, Jekaterina and Anderson, Carol Myrick and Blili-Hamelin, Borhane and Majumdar, Subhabrata}, booktitle = {ICML 2025 Workshop on Reliable and Responsible Foundation Models}, year = {2025}, url = {https://openreview.net/forum?id=ejvvhJZJSf}, } - EvalHuman-Centered Evaluation and Auditing of Language ModelsYu Lu Liu, Wesley Hanwen Deng, Michelle S Lam, and 6 more authorsIn Proceedings of the Extended Abstracts of the CHI Conference on Human Factors in Computing Systems, 2025
The recent advancements in Large Language Models (LLMs) have significantly impacted numerous, and will impact more, real-world applications. However, these models also pose significant risks to individuals and society. To mitigate these issues and guide future model development, responsible evaluation and auditing of LLMs are essential. This workshop aims to address the current “evaluation crisis” in LLM research and practice by bringing together HCI and AI researchers and practitioners to rethink LLM evaluation and auditing from a human-centered perspective. The workshop will explore topics around understanding stakeholders’ needs and goals with evaluation and auditing LLMs, establishing human-centered evaluation and auditing methods, developing tools and resources to support these methods, building community and fostering collaboration. By soliciting papers, organizing invited keynote and panel, and facilitating group discussions, this workshop aims to develop a future research agenda for addressing the challenges in LLM evaluation and auditing. Following a successful first iteration of this workshop at CHI 2024, we introduce the theme of “mind the context” for this second iteration, where participants will be encouraged to tackle the challenges and nuances of LLM evaluation and auditing in specific contexts.
@inproceedings{liu2025human, title = {Human-Centered Evaluation and Auditing of Language Models}, author = {Liu, Yu Lu and Deng, Wesley Hanwen and Lam, Michelle S and Eslami, Motahhare and Kim, Juho and Liao, Q Vera and Xu, Wei and Novikova, Jekaterina and Xiao, Ziang}, booktitle = {Proceedings of the Extended Abstracts of the CHI Conference on Human Factors in Computing Systems}, pages = {1--7}, year = {2025}, doi = {10.1145/3706599.3706729}, }
2024
- Eval
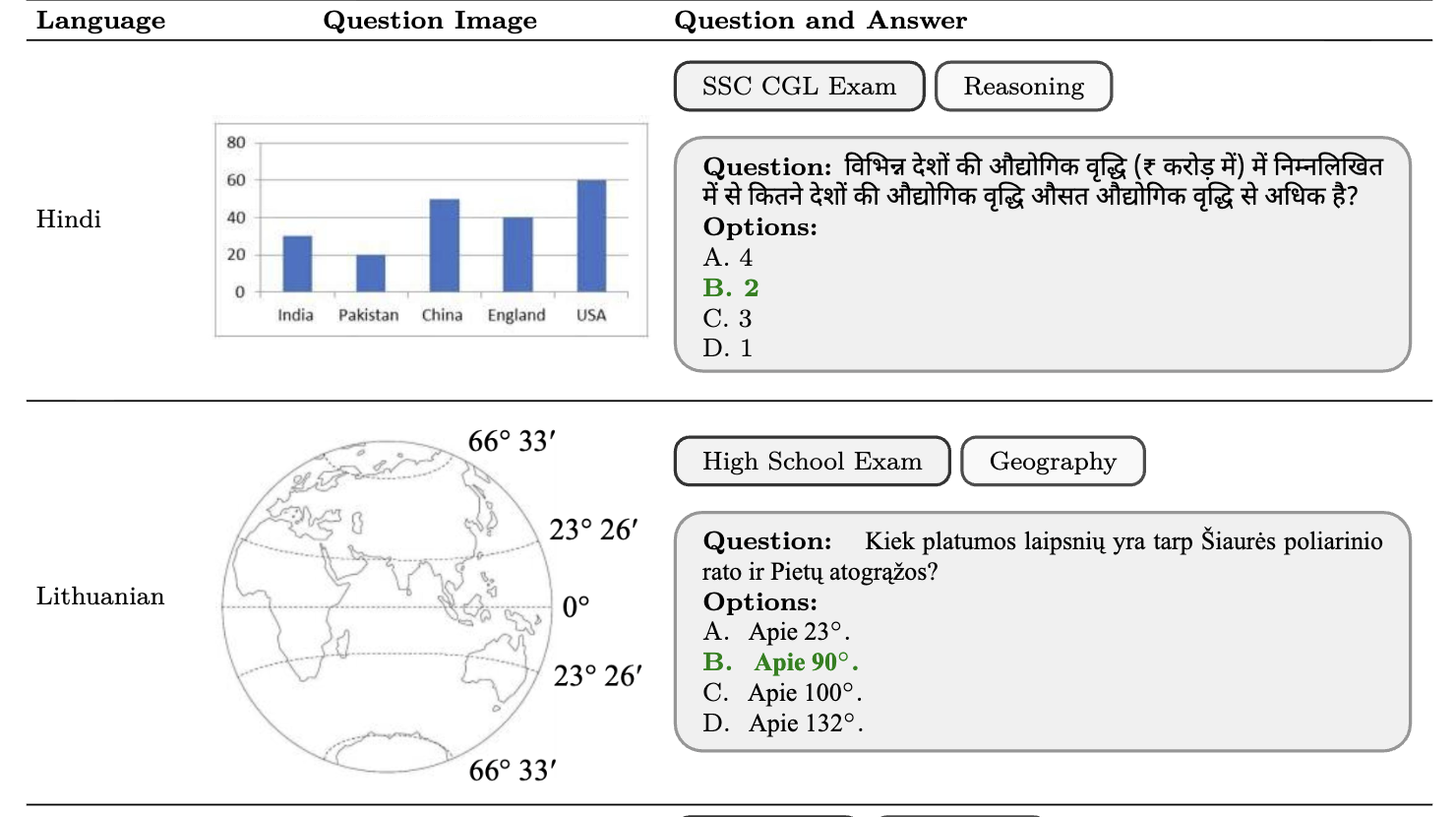 INCLUDE: Evaluating Multilingual Language Understanding with Regional KnowledgeAngelika Romanou, Negar Foroutan, Anna Sotnikova, and 54 more authorsIn The Thirteenth International Conference on Learning Representations, 2024
INCLUDE: Evaluating Multilingual Language Understanding with Regional KnowledgeAngelika Romanou, Negar Foroutan, Anna Sotnikova, and 54 more authorsIn The Thirteenth International Conference on Learning Representations, 2024Spotlight at ICLR 2025
The performance differential of large language models (LLM) between languages hinders their effective deployment in many regions, inhibiting the potential economic and societal value of generative AI tools in many communities. However, the development of functional LLMs in many languages (\ie, multilingual LLMs) is bottlenecked by the lack of high-quality evaluation resources in languages other than English. Moreover, current practices in multilingual benchmark construction often translate English resources, ignoring the regional and cultural knowledge of the environments in which multilingual systems would be used. In this work, we construct an evaluation suite of 197,243 QA pairs from local exam sources to measure the capabilities of multilingual LLMs in a variety of regional contexts. Our novel resource, INCLUDE, is a comprehensive knowledge- and reasoning-centric benchmark across 44 written languages that evaluates multilingual LLMs for performance in the actual language environments where they would be deployed.
@inproceedings{romanou2025include, title = {{INCLUDE}: Evaluating Multilingual Language Understanding with Regional Knowledge}, author = {Romanou, Angelika and Foroutan, Negar and Sotnikova, Anna and Nelaturu, Sree Harsha and Singh, Shivalika and Maheshwary, Rishabh and Altomare, Micol and Chen, Zeming and Haggag, Mohamed A. and A, Snegha and Amayuelas, Alfonso and Amirudin, Azril Hafizi and Boiko, Danylo and Chang, Michael and Chim, Jenny and Cohen, Gal and Dalmia, Aditya Kumar and Diress, Abraham and Duwal, Sharad and Dzenhaliou, Daniil and Florez, Daniel Fernando Erazo and Farestam, Fabian and Imperial, Joseph Marvin and Islam, Shayekh Bin and Isotalo, Perttu and Jabbarishiviari, Maral and Karlsson, B{\"o}rje F. and Khalilov, Eldar and Klamm, Christopher and Koto, Fajri and Krzemi{\'n}ski, Dominik and de Melo, Gabriel Adriano and Montariol, Syrielle and Nan, Yiyang and Niklaus, Joel and Novikova, Jekaterina and Ceron, Johan Samir Obando and Paul, Debjit and Ploeger, Esther and Purbey, Jebish and Rajwal, Swati and Ravi, Selvan Sunitha and Rydell, Sara and Santhosh, Roshan and Sharma, Drishti and Skenduli, Marjana Prifti and Moakhar, Arshia Soltani and soltani moakhar, Bardia and Tarun, Ayush Kumar and Wasi, Azmine Toushik and Weerasinghe, Thenuka Ovin and Yilmaz, Serhan and Zhang, Mike and Schlag, Imanol and Fadaee, Marzieh and Hooker, Sara and Bosselut, Antoine}, booktitle = {The Thirteenth International Conference on Learning Representations}, year = {2024}, url = {https://openreview.net/forum?id=k3gCieTXeY}, }
2023
- Open-Source
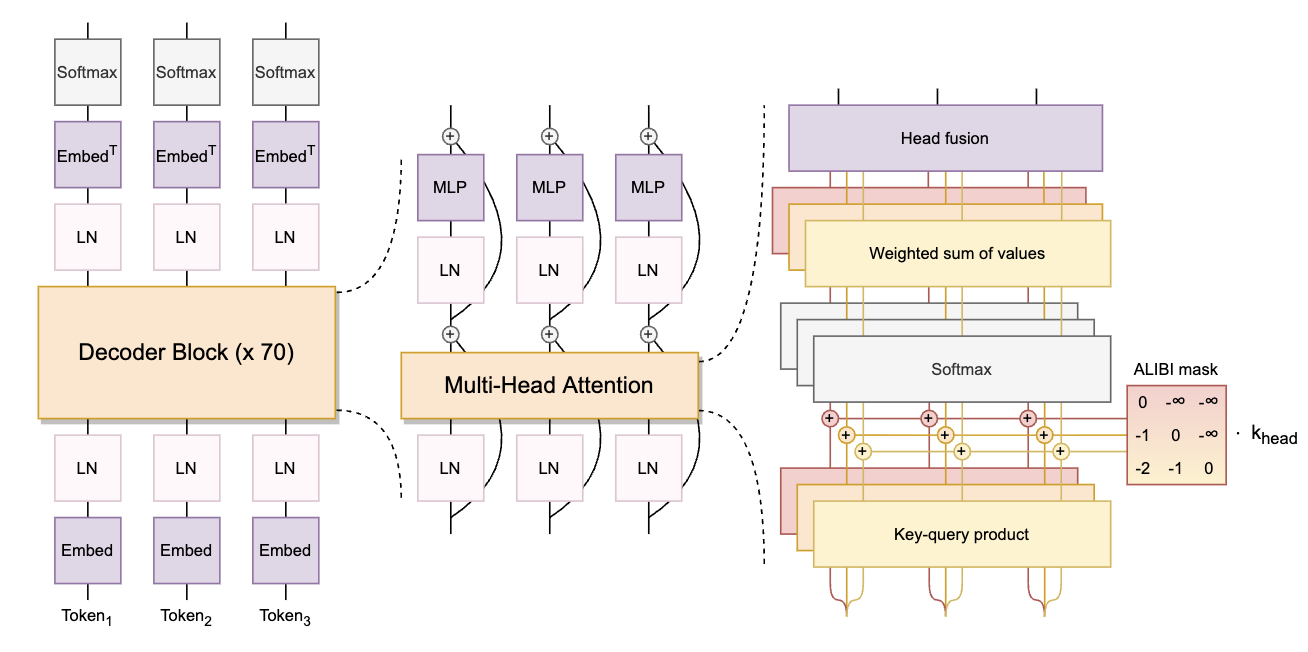 BLOOM: A 176B-Parameter Open-Access Multilingual Language ModelBigScience Workshop, :, Teven Le Scao, and 391 more authors2023
BLOOM: A 176B-Parameter Open-Access Multilingual Language ModelBigScience Workshop, :, Teven Le Scao, and 391 more authors2023Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
@misc{workshop2023bloom176bparameteropenaccessmultilingual, title = {BLOOM: A 176B-Parameter Open-Access Multilingual Language Model}, author = {Workshop, BigScience and : and Scao, Teven Le and Fan, Angela and Akiki, Christopher and Pavlick, Ellie and Ilić, Suzana and Hesslow, Daniel and Castagné, Roman and Luccioni, Alexandra Sasha and Yvon, François and Gallé, Matthias and Tow, Jonathan and Rush, Alexander M. and Biderman, Stella and Webson, Albert and Ammanamanchi, Pawan Sasanka and Wang, Thomas and Sagot, Benoît and Muennighoff, Niklas and del Moral, Albert Villanova and Ruwase, Olatunji and Bawden, Rachel and Bekman, Stas and McMillan-Major, Angelina and Beltagy, Iz and Nguyen, Huu and Saulnier, Lucile and Tan, Samson and Suarez, Pedro Ortiz and Sanh, Victor and Laurençon, Hugo and Jernite, Yacine and Launay, Julien and Mitchell, Margaret and Raffel, Colin and Gokaslan, Aaron and Simhi, Adi and Soroa, Aitor and Aji, Alham Fikri and Alfassy, Amit and Rogers, Anna and Nitzav, Ariel Kreisberg and Xu, Canwen and Mou, Chenghao and Emezue, Chris and Klamm, Christopher and Leong, Colin and van Strien, Daniel and Adelani, David Ifeoluwa and Radev, Dragomir and Ponferrada, Eduardo González and Levkovizh, Efrat and Kim, Ethan and Natan, Eyal Bar and Toni, Francesco De and Dupont, Gérard and Kruszewski, Germán and Pistilli, Giada and Elsahar, Hady and Benyamina, Hamza and Tran, Hieu and Yu, Ian and Abdulmumin, Idris and Johnson, Isaac and Gonzalez-Dios, Itziar and de la Rosa, Javier and Chim, Jenny and Dodge, Jesse and Zhu, Jian and Chang, Jonathan and Frohberg, Jörg and Tobing, Joseph and Bhattacharjee, Joydeep and Almubarak, Khalid and Chen, Kimbo and Lo, Kyle and Werra, Leandro Von and Weber, Leon and Phan, Long and allal, Loubna Ben and Tanguy, Ludovic and Dey, Manan and Muñoz, Manuel Romero and Masoud, Maraim and Grandury, María and Šaško, Mario and Huang, Max and Coavoux, Maximin and Singh, Mayank and Jiang, Mike Tian-Jian and Vu, Minh Chien and Jauhar, Mohammad A. and Ghaleb, Mustafa and Subramani, Nishant and Kassner, Nora and Khamis, Nurulaqilla and Nguyen, Olivier and Espejel, Omar and de Gibert, Ona and Villegas, Paulo and Henderson, Peter and Colombo, Pierre and Amuok, Priscilla and Lhoest, Quentin and Harliman, Rheza and Bommasani, Rishi and López, Roberto Luis and Ribeiro, Rui and Osei, Salomey and Pyysalo, Sampo and Nagel, Sebastian and Bose, Shamik and Muhammad, Shamsuddeen Hassan and Sharma, Shanya and Longpre, Shayne and Nikpoor, Somaieh and Silberberg, Stanislav and Pai, Suhas and Zink, Sydney and Torrent, Tiago Timponi and Schick, Timo and Thrush, Tristan and Danchev, Valentin and Nikoulina, Vassilina and Laippala, Veronika and Lepercq, Violette and Prabhu, Vrinda and Alyafeai, Zaid and Talat, Zeerak and Raja, Arun and Heinzerling, Benjamin and Si, Chenglei and Taşar, Davut Emre and Salesky, Elizabeth and Mielke, Sabrina J. and Lee, Wilson Y. and Sharma, Abheesht and Santilli, Andrea and Chaffin, Antoine and Stiegler, Arnaud and Datta, Debajyoti and Szczechla, Eliza and Chhablani, Gunjan and Wang, Han and Pandey, Harshit and Strobelt, Hendrik and Fries, Jason Alan and Rozen, Jos and Gao, Leo and Sutawika, Lintang and Bari, M Saiful and Al-shaibani, Maged S. and Manica, Matteo and Nayak, Nihal and Teehan, Ryan and Albanie, Samuel and Shen, Sheng and Ben-David, Srulik and Bach, Stephen H. and Kim, Taewoon and Bers, Tali and Fevry, Thibault and Neeraj, Trishala and Thakker, Urmish and Raunak, Vikas and Tang, Xiangru and Yong, Zheng-Xin and Sun, Zhiqing and Brody, Shaked and Uri, Yallow and Tojarieh, Hadar and Roberts, Adam and Chung, Hyung Won and Tae, Jaesung and Phang, Jason and Press, Ofir and Li, Conglong and Narayanan, Deepak and Bourfoune, Hatim and Casper, Jared and Rasley, Jeff and Ryabinin, Max and Mishra, Mayank and Zhang, Minjia and Shoeybi, Mohammad and Peyrounette, Myriam and Patry, Nicolas and Tazi, Nouamane and Sanseviero, Omar and von Platen, Patrick and Cornette, Pierre and Lavallée, Pierre François and Lacroix, Rémi and Rajbhandari, Samyam and Gandhi, Sanchit and Smith, Shaden and Requena, Stéphane and Patil, Suraj and Dettmers, Tim and Baruwa, Ahmed and Singh, Amanpreet and Cheveleva, Anastasia and Ligozat, Anne-Laure and Subramonian, Arjun and Névéol, Aurélie and Lovering, Charles and Garrette, Dan and Tunuguntla, Deepak and Reiter, Ehud and Taktasheva, Ekaterina and Voloshina, Ekaterina and Bogdanov, Eli and Winata, Genta Indra and Schoelkopf, Hailey and Kalo, Jan-Christoph and Novikova, Jekaterina and Forde, Jessica Zosa and Clive, Jordan and Kasai, Jungo and Kawamura, Ken and Hazan, Liam and Carpuat, Marine and Clinciu, Miruna and Kim, Najoung and Cheng, Newton and Serikov, Oleg and Antverg, Omer and van der Wal, Oskar and Zhang, Rui and Zhang, Ruochen and Gehrmann, Sebastian and Mirkin, Shachar and Pais, Shani and Shavrina, Tatiana and Scialom, Thomas and Yun, Tian and Limisiewicz, Tomasz and Rieser, Verena and Protasov, Vitaly and Mikhailov, Vladislav and Pruksachatkun, Yada and Belinkov, Yonatan and Bamberger, Zachary and Kasner, Zdeněk and Rueda, Alice and Pestana, Amanda and Feizpour, Amir and Khan, Ammar and Faranak, Amy and Santos, Ana and Hevia, Anthony and Unldreaj, Antigona and Aghagol, Arash and Abdollahi, Arezoo and Tammour, Aycha and HajiHosseini, Azadeh and Behroozi, Bahareh and Ajibade, Benjamin and Saxena, Bharat and Ferrandis, Carlos Muñoz and McDuff, Daniel and Contractor, Danish and Lansky, David and David, Davis and Kiela, Douwe and Nguyen, Duong A. and Tan, Edward and Baylor, Emi and Ozoani, Ezinwanne and Mirza, Fatima and Ononiwu, Frankline and Rezanejad, Habib and Jones, Hessie and Bhattacharya, Indrani and Solaiman, Irene and Sedenko, Irina and Nejadgholi, Isar and Passmore, Jesse and Seltzer, Josh and Sanz, Julio Bonis and Dutra, Livia and Samagaio, Mairon and Elbadri, Maraim and Mieskes, Margot and Gerchick, Marissa and Akinlolu, Martha and McKenna, Michael and Qiu, Mike and Ghauri, Muhammed and Burynok, Mykola and Abrar, Nafis and Rajani, Nazneen and Elkott, Nour and Fahmy, Nour and Samuel, Olanrewaju and An, Ran and Kromann, Rasmus and Hao, Ryan and Alizadeh, Samira and Shubber, Sarmad and Wang, Silas and Roy, Sourav and Viguier, Sylvain and Le, Thanh and Oyebade, Tobi and Le, Trieu and Yang, Yoyo and Nguyen, Zach and Kashyap, Abhinav Ramesh and Palasciano, Alfredo and Callahan, Alison and Shukla, Anima and Miranda-Escalada, Antonio and Singh, Ayush and Beilharz, Benjamin and Wang, Bo and Brito, Caio and Zhou, Chenxi and Jain, Chirag and Xu, Chuxin and Fourrier, Clémentine and Periñán, Daniel León and Molano, Daniel and Yu, Dian and Manjavacas, Enrique and Barth, Fabio and Fuhrimann, Florian and Altay, Gabriel and Bayrak, Giyaseddin and Burns, Gully and Vrabec, Helena U. and Bello, Imane and Dash, Ishani and Kang, Jihyun and Giorgi, John and Golde, Jonas and Posada, Jose David and Sivaraman, Karthik Rangasai and Bulchandani, Lokesh and Liu, Lu and Shinzato, Luisa and de Bykhovetz, Madeleine Hahn and Takeuchi, Maiko and Pàmies, Marc and Castillo, Maria A and Nezhurina, Marianna and Sänger, Mario and Samwald, Matthias and Cullan, Michael and Weinberg, Michael and Wolf, Michiel De and Mihaljcic, Mina and Liu, Minna and Freidank, Moritz and Kang, Myungsun and Seelam, Natasha and Dahlberg, Nathan and Broad, Nicholas Michio and Muellner, Nikolaus and Fung, Pascale and Haller, Patrick and Chandrasekhar, Ramya and Eisenberg, Renata and Martin, Robert and Canalli, Rodrigo and Su, Rosaline and Su, Ruisi and Cahyawijaya, Samuel and Garda, Samuele and Deshmukh, Shlok S and Mishra, Shubhanshu and Kiblawi, Sid and Ott, Simon and Sang-aroonsiri, Sinee and Kumar, Srishti and Schweter, Stefan and Bharati, Sushil and Laud, Tanmay and Gigant, Théo and Kainuma, Tomoya and Kusa, Wojciech and Labrak, Yanis and Bajaj, Yash Shailesh and Venkatraman, Yash and Xu, Yifan and Xu, Yingxin and Xu, Yu and Tan, Zhe and Xie, Zhongli and Ye, Zifan and Bras, Mathilde and Belkada, Younes and Wolf, Thomas}, year = {2023}, eprint = {2211.05100}, archiveprefix = {arXiv}, primaryclass = {cs.CL}, url = {https://arxiv.org/abs/2211.05100}, } - Eval
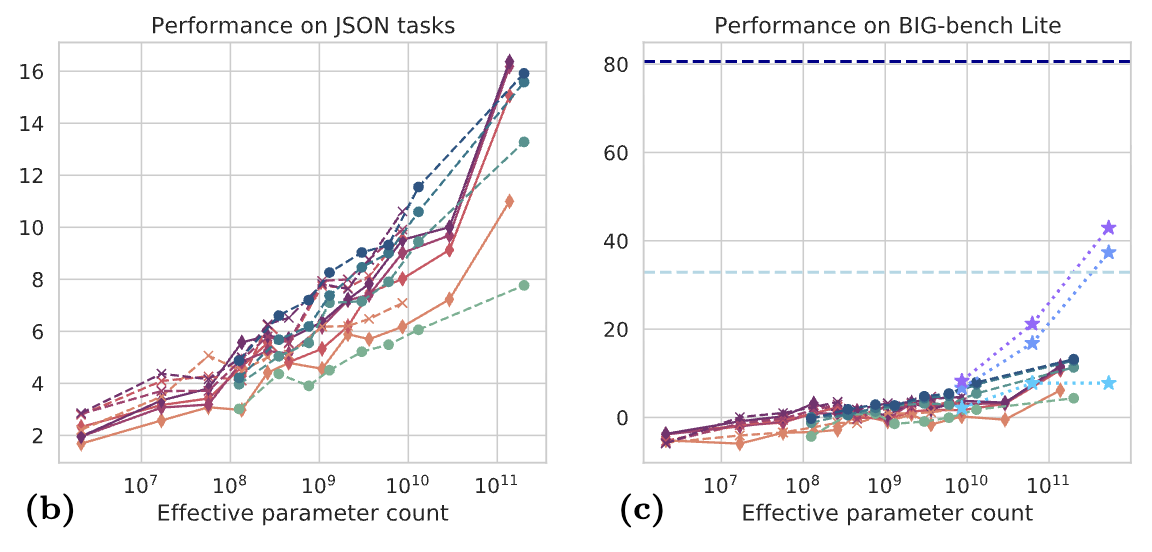 Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language modelsAarohi Srivastava, Abhinav Rastogi, Abhishek Rao, and 447 more authorsTransactions on Machine Learning Research, 2023
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language modelsAarohi Srivastava, Abhinav Rastogi, Abhishek Rao, and 447 more authorsTransactions on Machine Learning Research, 2023Featured Certification by the TMLR Outstanding Paper Committee
Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 450 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI’s GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit ’breakthrough’ behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
@article{srivastava2023beyond, title = {Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models}, author = {Srivastava, Aarohi and Rastogi, Abhinav and Rao, Abhishek and Shoeb, Abu Awal Md and Abid, Abubakar and Fisch, Adam and Brown, Adam R. and Santoro, Adam and Gupta, Aditya and Garriga-Alonso, Adri{\`a} and Kluska, Agnieszka and Lewkowycz, Aitor and Agarwal, Akshat and Power, Alethea and Ray, Alex and Warstadt, Alex and Kocurek, Alexander W. and Safaya, Ali and Tazarv, Ali and Xiang, Alice and Parrish, Alicia and Nie, Allen and Hussain, Aman and Askell, Amanda and Dsouza, Amanda and Slone, Ambrose and Rahane, Ameet and Iyer, Anantharaman S. and Andreassen, Anders Johan and Madotto, Andrea and Santilli, Andrea and Stuhlm{\"u}ller, Andreas and Dai, Andrew M. and La, Andrew and Lampinen, Andrew Kyle and Zou, Andy and Jiang, Angela and Chen, Angelica and Vuong, Anh and Gupta, Animesh and Gottardi, Anna and Norelli, Antonio and Venkatesh, Anu and Gholamidavoodi, Arash and Tabassum, Arfa and Menezes, Arul and Kirubarajan, Arun and Mullokandov, Asher and Sabharwal, Ashish and Herrick, Austin and Efrat, Avia and Erdem, Aykut and Karaka{\c{s}}, Ayla and Roberts, B. Ryan and Loe, Bao Sheng and Zoph, Barret and Bojanowski, Bart{\l}omiej and {\"O}zyurt, Batuhan and Hedayatnia, Behnam and Neyshabur, Behnam and Inden, Benjamin and Stein, Benno and Ekmekci, Berk and Lin, Bill Yuchen and Howald, Blake and Orinion, Bryan and Diao, Cameron and Dour, Cameron and Stinson, Catherine and Argueta, Cedrick and Ferri, Cesar and Singh, Chandan and Rathkopf, Charles and Meng, Chenlin and Baral, Chitta and Wu, Chiyu and Callison-Burch, Chris and Waites, Christopher and Voigt, Christian and Manning, Christopher D and Potts, Christopher and Ramirez, Cindy and Rivera, Clara E. and Siro, Clemencia and Raffel, Colin and Ashcraft, Courtney and Garbacea, Cristina and Sileo, Damien and Garrette, Dan and Hendrycks, Dan and Kilman, Dan and Roth, Dan and Freeman, C. Daniel and Khashabi, Daniel and Levy, Daniel and Gonz{\'a}lez, Daniel Mosegu{\'\i} and Perszyk, Danielle and Hernandez, Danny and Chen, Danqi and Ippolito, Daphne and Gilboa, Dar and Dohan, David and Drakard, David and Jurgens, David and Datta, Debajyoti and Ganguli, Deep and Emelin, Denis and Kleyko, Denis and Yuret, Deniz and Chen, Derek and Tam, Derek and Hupkes, Dieuwke and Misra, Diganta and Buzan, Dilyar and Mollo, Dimitri Coelho and Yang, Diyi and Lee, Dong-Ho and Schrader, Dylan and Shutova, Ekaterina and Cubuk, Ekin Dogus and Segal, Elad and Hagerman, Eleanor and Barnes, Elizabeth and Donoway, Elizabeth and Pavlick, Ellie and Rodol{\`a}, Emanuele and Lam, Emma and Chu, Eric and Tang, Eric and Erdem, Erkut and Chang, Ernie and Chi, Ethan A and Dyer, Ethan and Jerzak, Ethan and Kim, Ethan and Manyasi, Eunice Engefu and Zheltonozhskii, Evgenii and Xia, Fanyue and Siar, Fatemeh and Mart{\'\i}nez-Plumed, Fernando and Happ{\'e}, Francesca and Chollet, Francois and Rong, Frieda and Mishra, Gaurav and Winata, Genta Indra and de Melo, Gerard and Kruszewski, Germ{\`a}n and Parascandolo, Giambattista and Mariani, Giorgio and Wang, Gloria Xinyue and Jaimovitch-Lopez, Gonzalo and Betz, Gregor and Gur-Ari, Guy and Galijasevic, Hana and Kim, Hannah and Rashkin, Hannah and Hajishirzi, Hannaneh and Mehta, Harsh and Bogar, Hayden and Shevlin, Henry Francis Anthony and Schuetze, Hinrich and Yakura, Hiromu and Zhang, Hongming and Wong, Hugh Mee and Ng, Ian and Noble, Isaac and Jumelet, Jaap and Geissinger, Jack and Kernion, Jackson and Hilton, Jacob and Lee, Jaehoon and Fisac, Jaime Fern{\'a}ndez and Simon, James B and Koppel, James and Zheng, James and Zou, James and Kocon, Jan and Thompson, Jana and Wingfield, Janelle and Kaplan, Jared and Radom, Jarema and Sohl-Dickstein, Jascha and Phang, Jason and Wei, Jason and Yosinski, Jason and Novikova, Jekaterina and Bosscher, Jelle and Marsh, Jennifer and Kim, Jeremy and Taal, Jeroen and Engel, Jesse and Alabi, Jesujoba and Xu, Jiacheng and Song, Jiaming and Tang, Jillian and Waweru, Joan and Burden, John and Miller, John and Balis, John U. and Batchelder, Jonathan and Berant, Jonathan and Frohberg, J{\"o}rg and Rozen, Jos and Hernandez-Orallo, Jose and Boudeman, Joseph and Guerr, Joseph and Jones, Joseph and Tenenbaum, Joshua B. and Rule, Joshua S. and Chua, Joyce and Kanclerz, Kamil and Livescu, Karen and Krauth, Karl and Gopalakrishnan, Karthik and Ignatyeva, Katerina and Markert, Katja and Dhole, Kaustubh and Gimpel, Kevin and Omondi, Kevin and Mathewson, Kory Wallace and Chiafullo, Kristen and Shkaruta, Ksenia and Shridhar, Kumar and McDonell, Kyle and Richardson, Kyle and Reynolds, Laria and Gao, Leo and Zhang, Li and Dugan, Liam and Qin, Lianhui and Contreras-Ochando, Lidia and Morency, Louis-Philippe and Moschella, Luca and Lam, Lucas and Noble, Lucy and Schmidt, Ludwig and He, Luheng and Oliveros-Col{\'o}n, Luis and Metz, Luke and Senel, L{\"u}tfi Kerem and Bosma, Maarten and Sap, Maarten and Hoeve, Maartje Ter and Farooqi, Maheen and Faruqui, Manaal and Mazeika, Mantas and Baturan, Marco and Marelli, Marco and Maru, Marco and Ramirez-Quintana, Maria Jose and Tolkiehn, Marie and Giulianelli, Mario and Lewis, Martha and Potthast, Martin and Leavitt, Matthew L and Hagen, Matthias and Schubert, M{\'a}ty{\'a}s and Baitemirova, Medina Orduna and Arnaud, Melody and McElrath, Melvin and Yee, Michael Andrew and Cohen, Michael and Gu, Michael and Ivanitskiy, Michael and Starritt, Michael and Strube, Michael and Sw{\k{e}}drowski, Micha{\l} and Bevilacqua, Michele and Yasunaga, Michihiro and Kale, Mihir and Cain, Mike and Xu, Mimee and Suzgun, Mirac and Walker, Mitch and Tiwari, Mo and Bansal, Mohit and Aminnaseri, Moin and Geva, Mor and Gheini, Mozhdeh and T, Mukund Varma and Peng, Nanyun and Chi, Nathan Andrew and Lee, Nayeon and Krakover, Neta Gur-Ari and Cameron, Nicholas and Roberts, Nicholas and Doiron, Nick and Martinez, Nicole and Nangia, Nikita and Deckers, Niklas and Muennighoff, Niklas and Keskar, Nitish Shirish and Iyer, Niveditha S. and Constant, Noah and Fiedel, Noah and Wen, Nuan and Zhang, Oliver and Agha, Omar and Elbaghdadi, Omar and Levy, Omer and Evans, Owain and Casares, Pablo Antonio Moreno and Doshi, Parth and Fung, Pascale and Liang, Paul Pu and Vicol, Paul and Alipoormolabashi, Pegah and Liao, Peiyuan and Liang, Percy and Chang, Peter W and Eckersley, Peter and Htut, Phu Mon and Hwang, Pinyu and Mi{\l}kowski, Piotr and Patil, Piyush and Pezeshkpour, Pouya and Oli, Priti and Mei, Qiaozhu and Lyu, Qing and Chen, Qinlang and Banjade, Rabin and Rudolph, Rachel Etta and Gabriel, Raefer and Habacker, Rahel and Risco, Ramon and Milli{\`e}re, Rapha{\"e}l and Garg, Rhythm and Barnes, Richard and Saurous, Rif A. and Arakawa, Riku and Raymaekers, Robbe and Frank, Robert and Sikand, Rohan and Novak, Roman and Sitelew, Roman and Bras, Ronan Le and Liu, Rosanne and Jacobs, Rowan and Zhang, Rui and Salakhutdinov, Russ and Chi, Ryan Andrew and Lee, Seungjae Ryan and Stovall, Ryan and Teehan, Ryan and Yang, Rylan and Singh, Sahib and Mohammad, Saif M. and Anand, Sajant and Dillavou, Sam and Shleifer, Sam and Wiseman, Sam and Gruetter, Samuel and Bowman, Samuel R. and Schoenholz, Samuel Stern and Han, Sanghyun and Kwatra, Sanjeev and Rous, Sarah A. and Ghazarian, Sarik and Ghosh, Sayan and Casey, Sean and Bischoff, Sebastian and Gehrmann, Sebastian and Schuster, Sebastian and Sadeghi, Sepideh and Hamdan, Shadi and Zhou, Sharon and Srivastava, Shashank and Shi, Sherry and Singh, Shikhar and Asaadi, Shima and Gu, Shixiang Shane and Pachchigar, Shubh and Toshniwal, Shubham and Upadhyay, Shyam and Debnath, Shyamolima Shammie and Shakeri, Siamak and Thormeyer, Simon and Melzi, Simone and Reddy, Siva and Makini, Sneha Priscilla and Lee, Soo-Hwan and Torene, Spencer and Hatwar, Sriharsha and Dehaene, Stanislas and Divic, Stefan and Ermon, Stefano and Biderman, Stella and Lin, Stephanie and Prasad, Stephen and Piantadosi, Steven and Shieber, Stuart and Misherghi, Summer and Kiritchenko, Svetlana and Mishra, Swaroop and Linzen, Tal and Schuster, Tal and Li, Tao and Yu, Tao and Ali, Tariq and Hashimoto, Tatsunori and Wu, Te-Lin and Desbordes, Th{\'e}o and Rothschild, Theodore and Phan, Thomas and Wang, Tianle and Nkinyili, Tiberius and Schick, Timo and Kornev, Timofei and Tunduny, Titus and Gerstenberg, Tobias and Chang, Trenton and Neeraj, Trishala and Khot, Tushar and Shultz, Tyler and Shaham, Uri and Misra, Vedant and Demberg, Vera and Nyamai, Victoria and Raunak, Vikas and Ramasesh, Vinay Venkatesh and vinay uday prabhu and Padmakumar, Vishakh and Srikumar, Vivek and Fedus, William and Saunders, William and Zhang, William and Vossen, Wout and Ren, Xiang and Tong, Xiaoyu and Zhao, Xinran and Wu, Xinyi and Shen, Xudong and Yaghoobzadeh, Yadollah and Lakretz, Yair and Song, Yangqiu and Bahri, Yasaman and Choi, Yejin and Yang, Yichi and Hao, Sophie and Chen, Yifu and Belinkov, Yonatan and Hou, Yu and Hou, Yufang and Bai, Yuntao and Seid, Zachary and Zhao, Zhuoye and Wang, Zijian and Wang, Zijie J. and Wang, Zirui and Wu, Ziyi}, journal = {Transactions on Machine Learning Research}, issn = {2835-8856}, year = {2023}, url = {https://openreview.net/forum?id=uyTL5Bvosj}, }
2021
- High Stakes
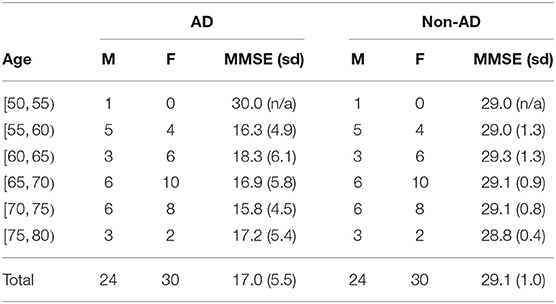 Comparing pre-trained and feature-based models for prediction of Alzheimer’s disease based on speechAparna Balagopalan, Benjamin Eyre, Jessica Robin, and 2 more authorsFrontiers in aging neuroscience, 2021
Comparing pre-trained and feature-based models for prediction of Alzheimer’s disease based on speechAparna Balagopalan, Benjamin Eyre, Jessica Robin, and 2 more authorsFrontiers in aging neuroscience, 2021Introduction: Research related to the automatic detection of Alzheimer’s disease (AD) is important, given the high prevalence of AD and the high cost of traditional diagnostic methods. Since AD significantly affects the content and acoustics of spontaneous speech, natural language processing, and machine learning provide promising techniques for reliably detecting AD. There has been a recent proliferation of classification models for AD, but these vary in the datasets used, model types and training and testing paradigms. In this study, we compare and contrast the performance of two common approaches for automatic AD detection from speech on the same, well-matched dataset, to determine the advantages of using domain knowledge vs. pre-trained transfer models. Methods: Audio recordings and corresponding manually-transcribed speech transcripts of a picture description task administered to 156 demographically matched older adults, 78 with Alzheimer’s Disease (AD) and 78 cognitively intact (healthy) were classified using machine learning and natural language processing as “AD” or “non-AD.” The audio was acoustically-enhanced, and post-processed to improve quality of the speech recording as well control for variation caused by recording conditions. Two approaches were used for classification of these speech samples: (1) using domain knowledge: extracting an extensive set of clinically relevant linguistic and acoustic features derived from speech and transcripts based on prior literature, and (2) using transfer-learning and leveraging large pre-trained machine learning models: using transcript-representations that are automatically derived from state-of-the-art pre-trained language models, by fine-tuning Bidirectional Encoder Representations from Transformer (BERT)-based sequence classification models. Results: We compared the utility of speech transcript representations obtained from recent natural language processing models (i.e., BERT) to more clinically-interpretable language feature-based methods. Both the feature-based approaches and fine-tuned BERT models significantly outperformed the baseline linguistic model using a small set of linguistic features, demonstrating the importance of extensive linguistic information for detecting cognitive impairments relating to AD. We observed that fine-tuned BERT models numerically outperformed feature-based approaches on the AD detection task, but the difference was not statistically significant. Our main contribution is the observation that when tested on the same, demographically balanced dataset and tested on independent, unseen data, both domain knowledge and pretrained linguistic models have good predictive performance for detecting AD based on speech. It is notable that linguistic information alone is capable of achieving comparable, and even numerically better, performance than models including both acoustic and linguistic features here. We also try to shed light on the inner workings of the more black-box natural language processing model by performing an interpretability analysis, and find that attention weights reveal interesting patterns such as higher attribution to more important information content units in the picture description task, as well as pauses and filler words. Conclusion: This approach supports the value of well-performing machine learning and linguistically-focussed processing techniques to detect AD from speech and highlights the need to compare model performance on carefully balanced datasets, using consistent same training parameters and independent test datasets in order to determine the best performing predictive model.
@article{balagopalan2021comparing, title = {Comparing pre-trained and feature-based models for prediction of Alzheimer's disease based on speech}, author = {Balagopalan, Aparna and Eyre, Benjamin and Robin, Jessica and Rudzicz, Frank and Novikova, Jekaterina}, journal = {Frontiers in aging neuroscience}, volume = {13}, doi = {10.3389/fnagi.2021.635945}, dimensions = {true}, pages = {635945}, year = {2021}, publisher = {Frontiers Media SA} } - High Stakes
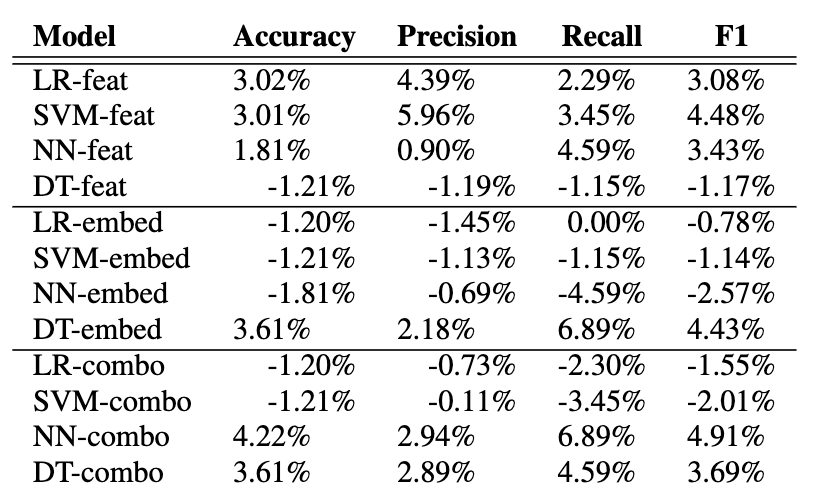 Comparing Acoustic-Based Approaches for Alzheimer’s Disease DetectionAparna Balagopalan and Jekaterina NovikovaIn Interspeech 2021, 2021
Comparing Acoustic-Based Approaches for Alzheimer’s Disease DetectionAparna Balagopalan and Jekaterina NovikovaIn Interspeech 2021, 2021Robust strategies for Alzheimer’s disease (AD) detection is important, given the high prevalence of AD. In this paper, we study the performance and generalizability of three approaches for AD detection from speech on the recent ADReSSo challenge dataset:1) using conventional acoustic features 2) using novel pre-trained acoustic embeddings 3) combining acoustic features and embeddings. We find that while feature-based approaches have a higher precision, classification approaches relying on the combination of embeddings and features prove to have a higher, and more balanced performance across multiple metrics of performance. Our best model, using such a combined approach, outperforms the acoustic baseline in the challenge by 2.8%.
@inproceedings{balagopalan21_interspeech, title = {Comparing Acoustic-Based Approaches for Alzheimer’s Disease Detection}, author = {Balagopalan, Aparna and Novikova, Jekaterina}, year = {2021}, booktitle = {Interspeech 2021}, pages = {3800--3804}, doi = {10.21437/Interspeech.2021-759}, issn = {2958-1796}, dimensions = {true}, }
2020
- Eval
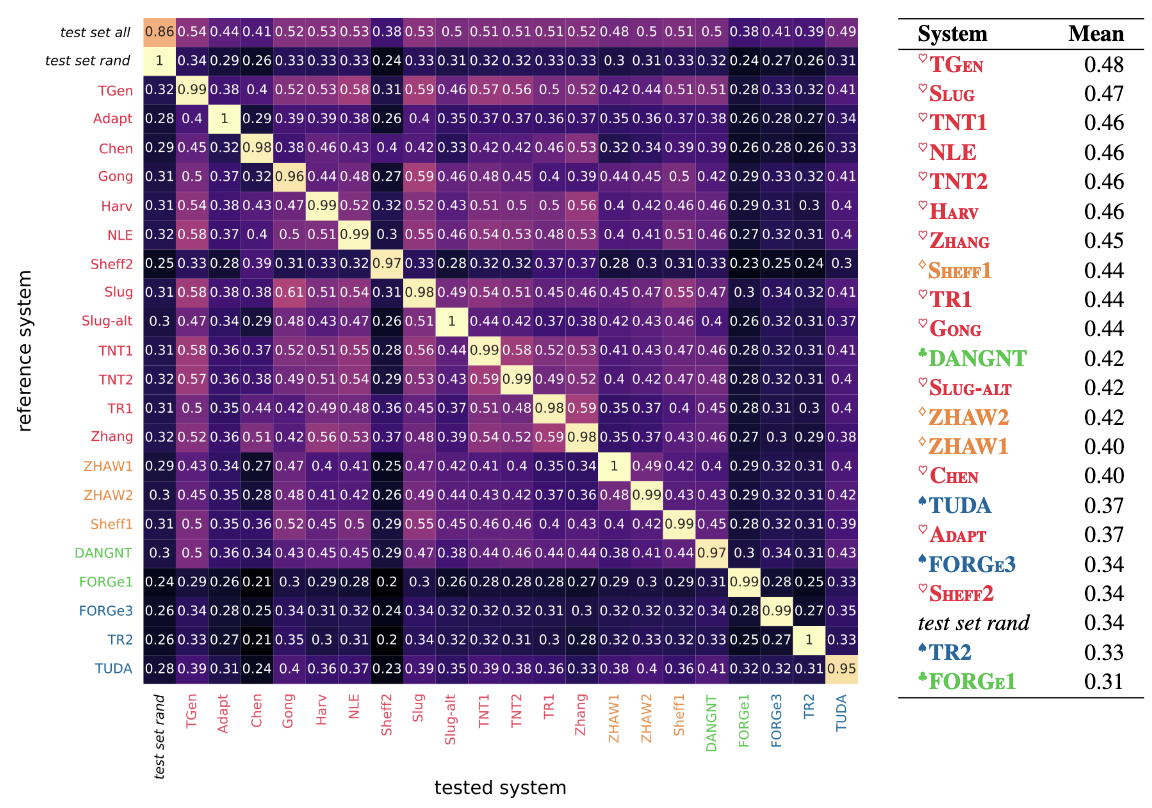 Evaluating the state-of-the-art of End-to-End Natural Language Generation: The E2E NLG challengeOndřej Dušek, Jekaterina Novikova, and Verena RieserComput. Speech Lang., Jan 2020
Evaluating the state-of-the-art of End-to-End Natural Language Generation: The E2E NLG challengeOndřej Dušek, Jekaterina Novikova, and Verena RieserComput. Speech Lang., Jan 2020This paper provides a comprehensive analysis of the first shared task on End-to-End Natural Language Generation (NLG) and identifies avenues for future research based on the results. This shared task aimed to assess whether recent end-to-end NLG systems can generate more complex output by learning from datasets containing higher lexical richness, syntactic complexity and diverse discourse phenomena. Introducing novel automatic and human metrics, we compare 62 systems submitted by 17 institutions, covering a wide range of approaches, including machine learning architectures – with the majority implementing sequence-to-sequence models (seq2seq) – as well as systems based on grammatical rules and templates. Seq2seq-based systems have demonstrated a great potential for NLG in the challenge. We find that seq2seq systems generally score high in terms of word-overlap metrics and human evaluations of naturalness – with the winning Slug system (Juraska et al., 2018) being seq2seq-based. However, vanilla seq2seq models often fail to correctly express a given meaning representation if they lack a strong semantic control mechanism applied during decoding. Moreover, seq2seq models can be outperformed by hand-engineered systems in terms of overall quality, as well as complexity, length and diversity of outputs. This research has influenced, inspired and motivated a number of recent studies outwith the original competition, which we also summarise as part of this paper.
@article{10.1016/j.csl.2019.06.009, author = {Du\v{s}ek, Ond\v{r}ej and Novikova, Jekaterina and Rieser, Verena}, title = {Evaluating the state-of-the-art of End-to-End Natural Language Generation: The E2E NLG challenge}, year = {2020}, issue_date = {Jan 2020}, publisher = {Academic Press Ltd.}, address = {GBR}, volume = {59}, number = {C}, issn = {0885-2308}, url = {https://doi.org/10.1016/j.csl.2019.06.009}, doi = {10.1016/j.csl.2019.06.009}, journal = {Comput. Speech Lang.}, month = jan, pages = {123–156}, numpages = {34}, dimensions = {true}, } - High Stakes
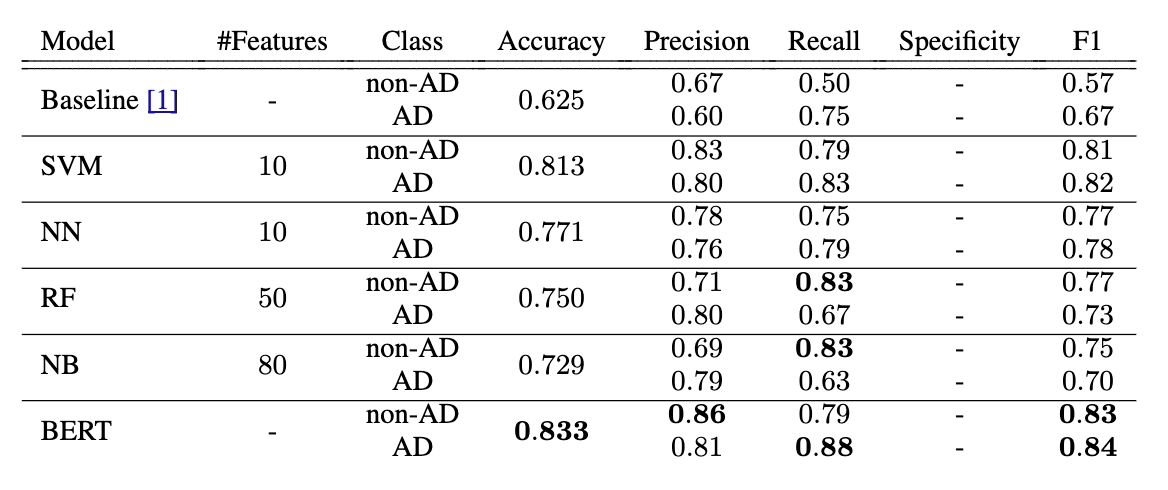 To BERT or not to BERT: Comparing Speech and Language-Based Approaches for Alzheimer’s Disease DetectionAparna Balagopalan, Benjamin Eyre, Frank Rudzicz, and 1 more authorIn Interspeech 2020, Jan 2020
To BERT or not to BERT: Comparing Speech and Language-Based Approaches for Alzheimer’s Disease DetectionAparna Balagopalan, Benjamin Eyre, Frank Rudzicz, and 1 more authorIn Interspeech 2020, Jan 2020Research related to automatically detecting Alzheimer’s disease (AD) is important, given the high prevalence of AD and the high cost of traditional methods. Since AD significantly affects the content and acoustics of spontaneous speech, natural language processing and machine learning provide promising techniques for reliably detecting AD. We compare and contrast the performance of two such approaches for AD detection on the recent ADReSS challenge dataset: 1) using domain knowledge-based hand-crafted features that capture linguistic and acoustic phenomena, and 2) fine-tuning Bidirectional Encoder Representations from Transformer (BERT)-based sequence classification models. We also compare multiple feature-based regression models for a neuropsychological score task in the challenge. We observe that fine-tuned BERT models, given the relative importance of linguistics in cognitive impairment detection, outperform feature-based approaches on the AD detection task.
@inproceedings{balagopalan20_interspeech, title = {To BERT or not to BERT: Comparing Speech and Language-Based Approaches for Alzheimer’s Disease Detection}, author = {Balagopalan, Aparna and Eyre, Benjamin and Rudzicz, Frank and Novikova, Jekaterina}, year = {2020}, booktitle = {Interspeech 2020}, pages = {2167--2171}, doi = {10.21437/Interspeech.2020-2557}, issn = {2958-1796}, dimensions = {true}, }
2019
- High Stakes
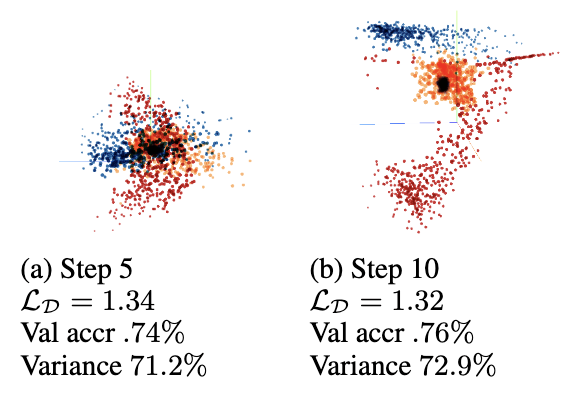 Detecting cognitive impairments by agreeing on interpretations of linguistic featuresZining Zhu, Jekaterina Novikova, and Frank RudziczIn Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Jun 2019
Detecting cognitive impairments by agreeing on interpretations of linguistic featuresZining Zhu, Jekaterina Novikova, and Frank RudziczIn Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Jun 2019Linguistic features have shown promising applications for detecting various cognitive impairments. To improve detection accuracies, increasing the amount of data or the number of linguistic features have been two applicable approaches. However, acquiring additional clinical data can be expensive, and hand-crafting features is burdensome. In this paper, we take a third approach, proposing Consensus Networks (CNs), a framework to classify after reaching agreements between modalities. We divide linguistic features into non-overlapping subsets according to their modalities, and let neural networks learn low-dimensional representations that agree with each other. These representations are passed into a classifier network. All neural networks are optimized iteratively. In this paper, we also present two methods that improve the performance of CNs. We then present ablation studies to illustrate the effectiveness of modality division. To understand further what happens in CNs, we visualize the representations during training. Overall, using all of the 413 linguistic features, our models significantly outperform traditional classifiers, which are used by the state-of-the-art papers.
@inproceedings{zhu-etal-2019-detecting, title = {Detecting cognitive impairments by agreeing on interpretations of linguistic features}, author = {Zhu, Zining and Novikova, Jekaterina and Rudzicz, Frank}, editor = {Burstein, Jill and Doran, Christy and Solorio, Thamar}, booktitle = {Proceedings of the 2019 Conference of the North {A}merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers)}, month = jun, year = {2019}, address = {Minneapolis, Minnesota}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/N19-1146/}, doi = {10.18653/v1/N19-1146}, pages = {1431--1441}, dimensions = {true}, }
2018
- Eval
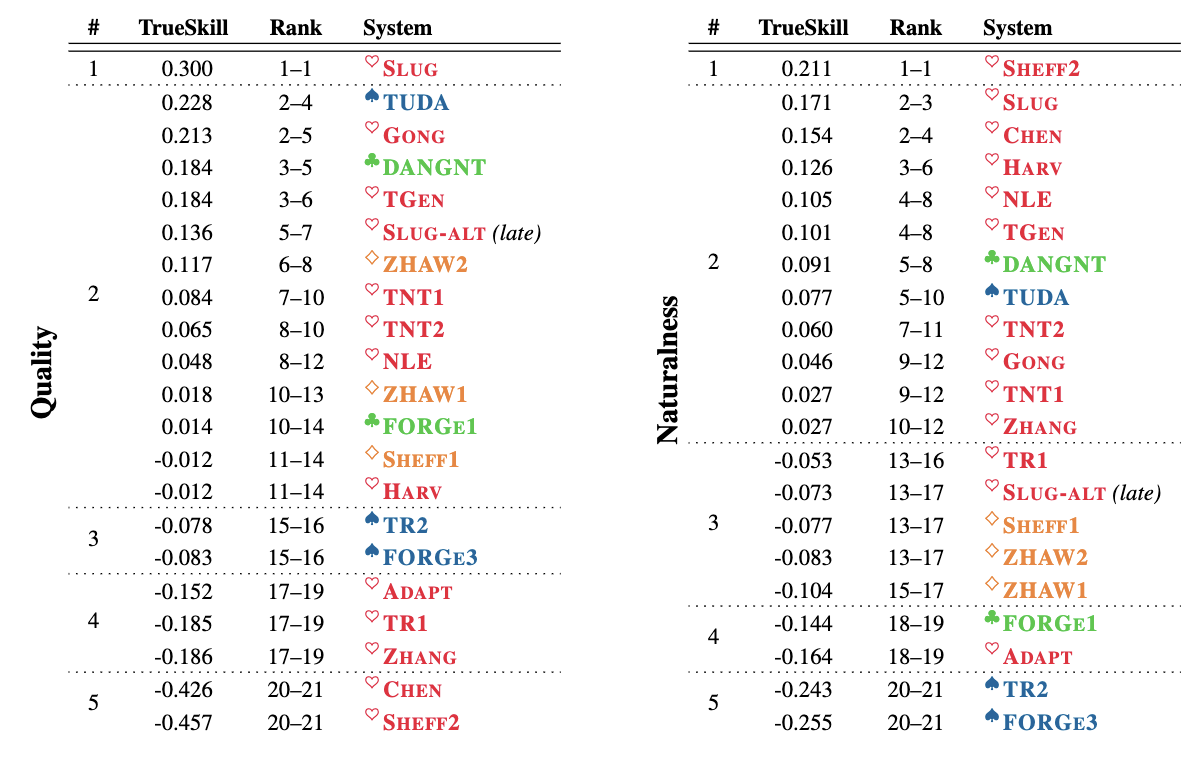 Findings of the E2E NLG ChallengeOndřej Dušek, Jekaterina Novikova, and Verena RieserIn Proceedings of the 11th International Conference on Natural Language Generation, Nov 2018
Findings of the E2E NLG ChallengeOndřej Dušek, Jekaterina Novikova, and Verena RieserIn Proceedings of the 11th International Conference on Natural Language Generation, Nov 2018This paper summarises the experimental setup and results of the first shared task on end-to-end (E2E) natural language generation (NLG) in spoken dialogue systems. Recent end-to-end generation systems are promising since they reduce the need for data annotation. However, they are currently limited to small, delexicalised datasets. The E2E NLG shared task aims to assess whether these novel approaches can generate better-quality output by learning from a dataset containing higher lexical richness, syntactic complexity and diverse discourse phenomena. We compare 62 systems submitted by 17 institutions, covering a wide range of approaches, including machine learning architectures – with the majority implementing sequence-to-sequence models (seq2seq) – as well as systems based on grammatical rules and templates.
@inproceedings{dusek-etal-2018-findings, title = {Findings of the {E}2{E} {NLG} Challenge}, author = {Du{\v{s}}ek, Ond{\v{r}}ej and Novikova, Jekaterina and Rieser, Verena}, editor = {Krahmer, Emiel and Gatt, Albert and Goudbeek, Martijn}, booktitle = {Proceedings of the 11th International Conference on Natural Language Generation}, month = nov, year = {2018}, address = {Tilburg University, The Netherlands}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/W18-6539/}, doi = {10.18653/v1/W18-6539}, pages = {322--328}, dimensions = {true}, } - Eval
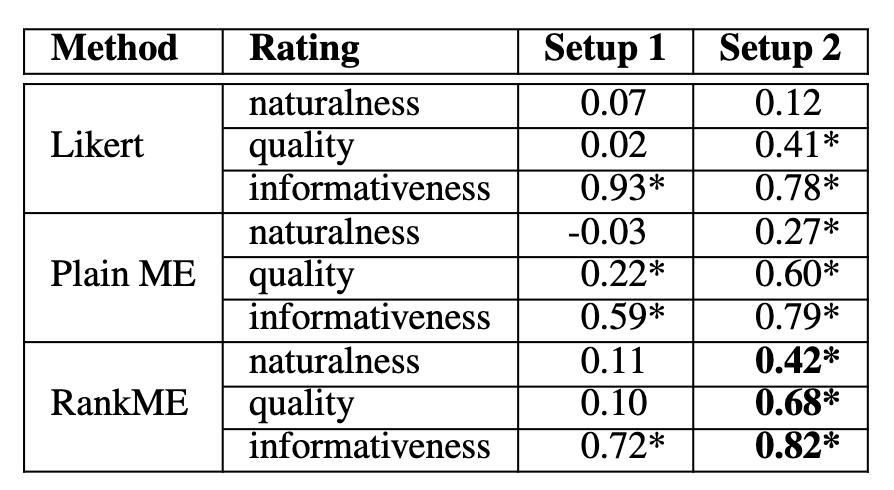 RankME: Reliable Human Ratings for Natural Language GenerationJekaterina Novikova, Ondřej Dušek, and Verena RieserIn Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), Jun 2018
RankME: Reliable Human Ratings for Natural Language GenerationJekaterina Novikova, Ondřej Dušek, and Verena RieserIn Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), Jun 2018Human evaluation for natural language generation (NLG) often suffers from inconsistent user ratings. While previous research tends to attribute this problem to individual user preferences, we show that the quality of human judgements can also be improved by experimental design. We present a novel rank-based magnitude estimation method (RankME), which combines the use of continuous scales and relative assessments. We show that RankME significantly improves the reliability and consistency of human ratings compared to traditional evaluation methods. In addition, we show that it is possible to evaluate NLG systems according to multiple, distinct criteria, which is important for error analysis. Finally, we demonstrate that RankME, in combination with Bayesian estimation of system quality, is a cost-effective alternative for ranking multiple NLG systems.
@inproceedings{novikova-etal-2018-rankme, title = {{R}ank{ME}: Reliable Human Ratings for Natural Language Generation}, author = {Novikova, Jekaterina and Du{\v{s}}ek, Ond{\v{r}}ej and Rieser, Verena}, editor = {Walker, Marilyn and Ji, Heng and Stent, Amanda}, booktitle = {Proceedings of the 2018 Conference of the North {A}merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers)}, month = jun, year = {2018}, address = {New Orleans, Louisiana}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/N18-2012/}, doi = {10.18653/v1/N18-2012}, pages = {72--78}, dimensions = {true}, }
2017
- Eval
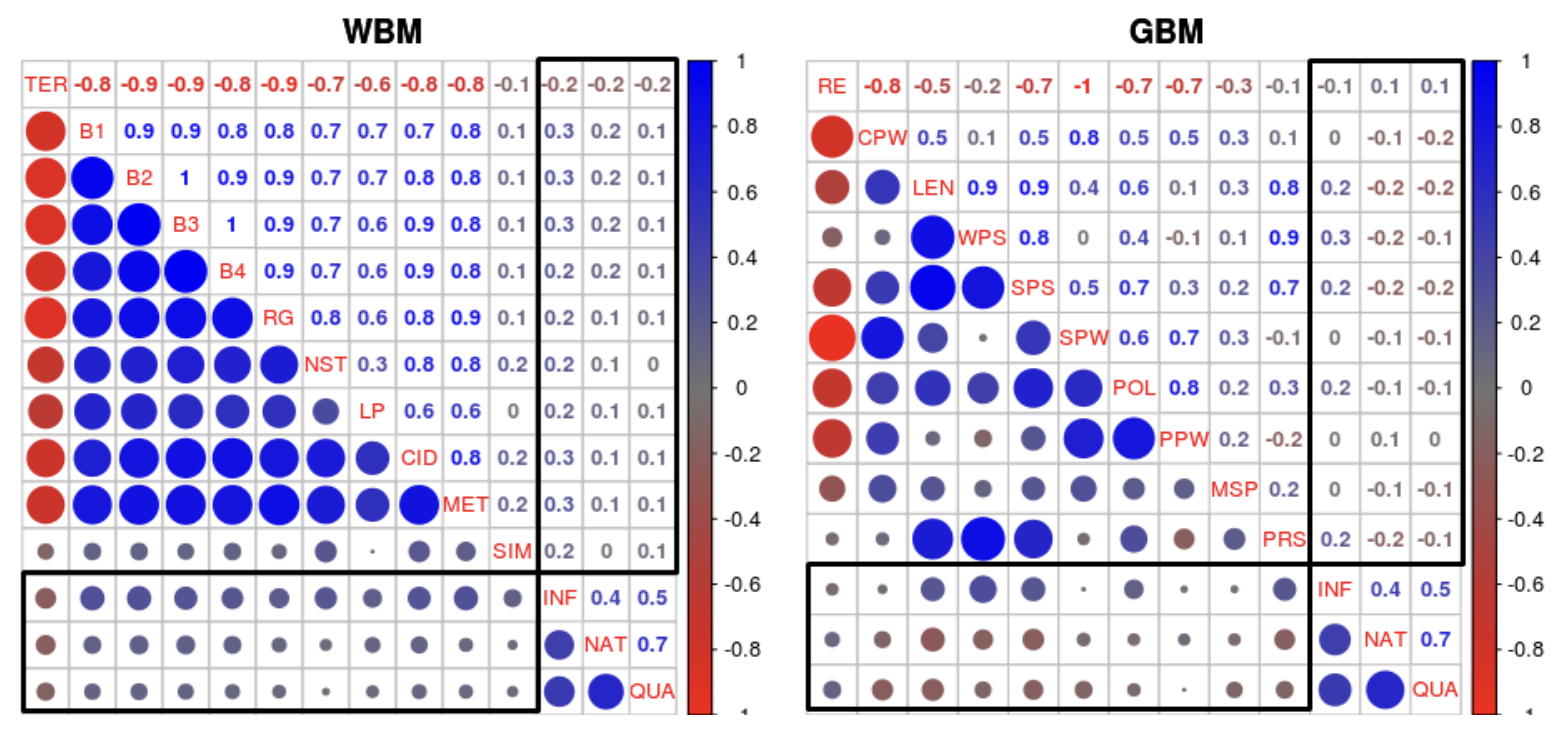 Why We Need New Evaluation Metrics for NLGJekaterina Novikova, Ondřej Dušek, Amanda Cercas Curry, and 1 more authorIn Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Sep 2017
Why We Need New Evaluation Metrics for NLGJekaterina Novikova, Ondřej Dušek, Amanda Cercas Curry, and 1 more authorIn Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Sep 2017The majority of NLG evaluation relies on automatic metrics, such as BLEU . In this paper, we motivate the need for novel, system- and data-independent automatic evaluation methods: We investigate a wide range of metrics, including state-of-the-art word-based and novel grammar-based ones, and demonstrate that they only weakly reflect human judgements of system outputs as generated by data-driven, end-to-end NLG. We also show that metric performance is data- and system-specific. Nevertheless, our results also suggest that automatic metrics perform reliably at system-level and can support system development by finding cases where a system performs poorly.
@inproceedings{novikova-etal-2017-need, title = {Why We Need New Evaluation Metrics for {NLG}}, author = {Novikova, Jekaterina and Du{\v{s}}ek, Ond{\v{r}}ej and Cercas Curry, Amanda and Rieser, Verena}, editor = {Palmer, Martha and Hwa, Rebecca and Riedel, Sebastian}, booktitle = {Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing}, month = sep, year = {2017}, address = {Copenhagen, Denmark}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/D17-1238/}, doi = {10.18653/v1/D17-1238}, pages = {2241--2252}, dimensions = {true}, } - Eval
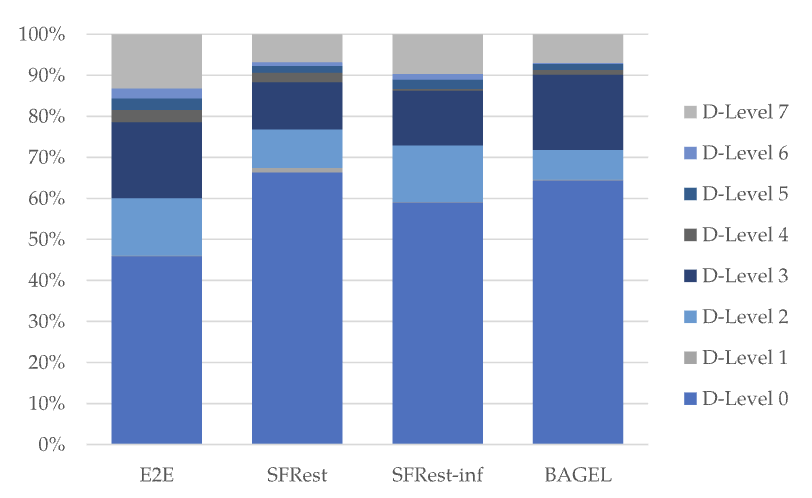 The E2E Dataset: New Challenges For End-to-End GenerationJekaterina Novikova, Ondřej Dušek, and Verena RieserIn Proceedings of the 18th Annual SIGdial Meeting on Discourse and Dialogue, Aug 2017
The E2E Dataset: New Challenges For End-to-End GenerationJekaterina Novikova, Ondřej Dušek, and Verena RieserIn Proceedings of the 18th Annual SIGdial Meeting on Discourse and Dialogue, Aug 2017Best Paper Nomination at SIGDIAL 2017
This paper describes the E2E data, a new dataset for training end-to-end, data-driven natural language generation systems in the restaurant domain, which is ten times bigger than existing, frequently used datasets in this area. The E2E dataset poses new challenges: (1) its human reference texts show more lexical richness and syntactic variation, including discourse phenomena; (2) generating from this set requires content selection. As such, learning from this dataset promises more natural, varied and less template-like system utterances. We also establish a baseline on this dataset, which illustrates some of the difficulties associated with this data.
@inproceedings{novikova-etal-2017-e2e, title = {The {E}2{E} Dataset: New Challenges For End-to-End Generation}, author = {Novikova, Jekaterina and Du{\v{s}}ek, Ond{\v{r}}ej and Rieser, Verena}, editor = {Jokinen, Kristiina and Stede, Manfred and DeVault, David and Louis, Annie}, booktitle = {Proceedings of the 18th Annual {SIG}dial Meeting on Discourse and Dialogue}, month = aug, year = {2017}, address = {Saarbr{\"u}cken, Germany}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/W17-5525/}, doi = {10.18653/v1/W17-5525}, pages = {201--206}, dimensions = {true}, }